Hugo and Lambda
I made a post a few days ago about being able to post using my phone, so here’s some more info!
Disclaimer: I work at Amazon on the AWS Lambda team.
This blog is written using Hugo, which is a static website generator. This means after I write a post, I must generate the static HTML files that I then upload into an S3 bucket that is used to serve the content to you, the reader. I like static sites because conceptually they’re simple: all the server has to do is send files to the client. The one thing I don’t like is the generation step because you have to set up your computer with the right tools, run the tools, then upload the output to where it’s being hosted. It’s not rocket science, but it’s something I’d like to think about less.
The source code for this blog is stored in a GitHub repository, so conceptually what I wanted was this: whenever a change is made to that repository, re-generate the site and upload the output to S3. AWS Lambda is a good candidate to take care of this for me.
The first step is use GitHub Webhooks to send a notification when any change happens to the source code repository. This notification comes in the form of an HTTP POST request sent to an endpoint you define. I used API Gateway to set up an endpoint that will receive that notification and forward the request to Lambda.
The request that the GitHub Webhook sends must complete in 10 seconds or less, so I actually wrote two Lambda functions that separate accepting work from GitHub and doing the work:
- API Lambda - this function sits behind the API Gateway endpoint. It:
- Receives and parses the GitHub Webhook request.
- Does validation that the request actually came from GitHub by checking the defined secret.
- Asynchronously calls the Builder Lambda that does the heavy lifting.
- Builder Lambda - this function does the generation of the site. It:
- Clones the most recent code out of the GitHub repository.
- Uses the copy of
hugobundled with the Lambda function to generate the static HTML that makes up the site. One reason why I love Hugo is that it’s just one big executable so incorporating it into a Lambda function was super easy. No crazy dependencies or toolchains to pull in, just bundle the executable into your .zip. - Syncs the static HTML from the Hugo output directory to the defined S3 bucket.
- Submits an invalidation to CloudFront.
Here’s a diagram of the overall flow I whipped up using draw.io:
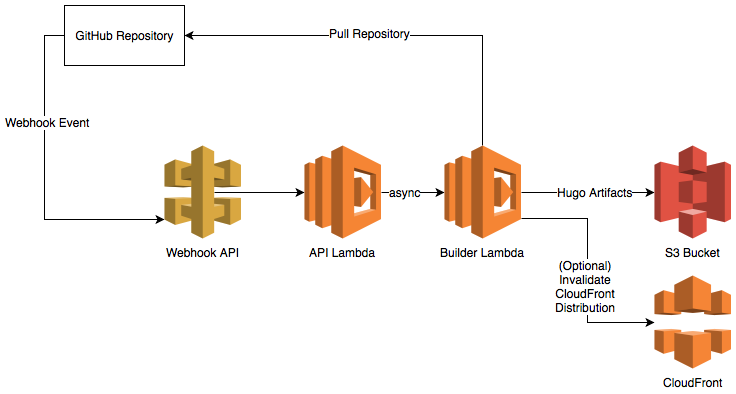
This works quite well and takes about 30 seconds from GitHub repository push to the change being live on my blog.
I made all the code that I use available on GitHub. Please feel free to use it, change it, or give feedback!
One of the reasons I like hosting my own content is that it gives me the opportunity to play around with some toy problems and experiment with different tools. I find this kind of stuff fun!
TODO:
- Doing full CloudFront invalidations on updates feels goofy, there’s gotta be a better way.
- Need to set
Cache-Controlheaders/metadata appropriately on images. - Get the API Lambda and Builder Lambda to be more easily deployable. AWS SAM? Serverless framework?
UPDATE 9/14/2018:
I made some changes to set Cache-Control headers in a sane way when syncing to S3, which has eliminated the need for CloudFront invalidations.